
So I’ve been informally experimenting with the effect of reading aloud in math class.

Many years ago, I noticed that when a student couldn’t get started on a task on their own, they’d raise their hand and claim “I don’t know what to do.” I would ask, “Well, what did the problem say?” The student would then answer, “I don’t know.” My next step would then be to read the problem aloud and ask “What do you think you’re supposed to do?” The student would respond to this question…and most often with the correct response.
I didn’t need to ask the students any questions related to the math at hand. They just needed to hear the problem aloud.
I started to pay attention to this back and forth that I would have with countless numbers of students. And then began to explore the question-what if they read aloud to themselves???
An eight grade honors level student came to find me because she couldn’t figure out a problem she had on an assignment. I said read the problem. She said “I already did.” I asked her to read it aloud to me. I could see the lightbulb go off when she finished and she asked “Am I supposed to _______?” And she was correct!
Two nights ago, my fourth grader that was accepted into the STEM program in our district, was working on an online assignment in the other room. He came out to my husband and I and asked for help because he was stuck. He sat down next to my husband and began reading the problem out loud to him. As soon as he finished, he said, “Oh, never mind! I know what to do.”
I’ve noticed that I will often put my fingers on my ears and read-aloud in a whisper if I’m trying to double check the words that I’ve written. It’s helpful to hear myself. How can we explore this more with students? How can we incorporate this in our classrooms?
I did a quick search attempting to find research on this topic. I noted this article about reading aloud for English language learners. But what was interesting was this:

I’m interested in researching this further and would definitely love to know if anyone has had similar experiences with their students.


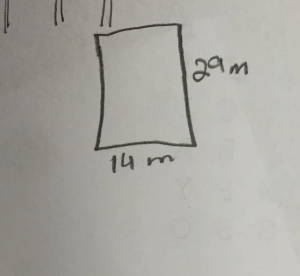
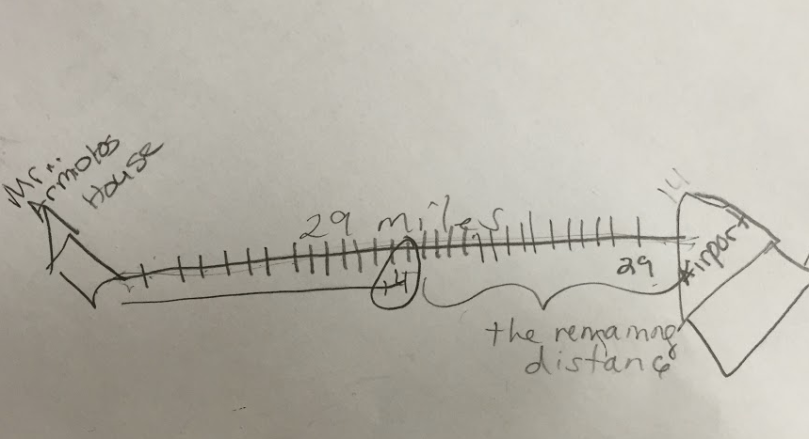
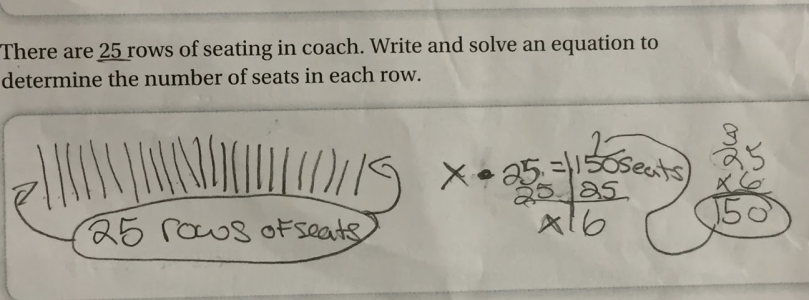










 is 125. So, I said well let’s write that down.
is 125. So, I said well let’s write that down. is 25.
is 25.